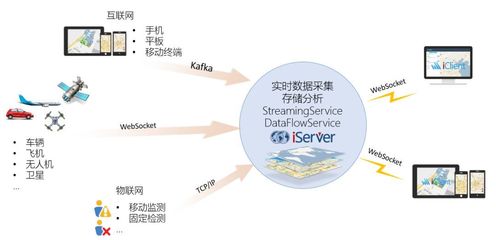
筑牢科研数据基石 中国科学院科学数据库的备份与集中管理服务
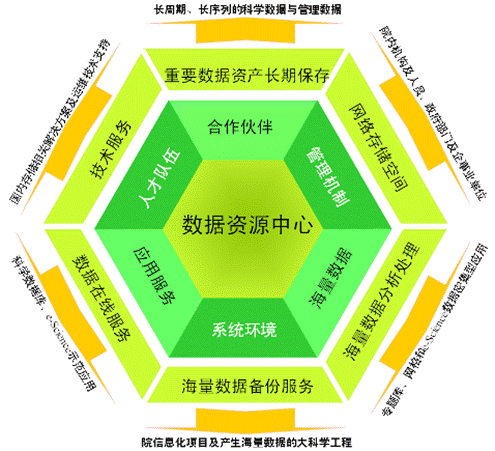
在当今数据驱动的科研时代,中国科学院(以下简称“中科院”)作为国家战略科技力量的核心,其产出的科学数据是国家宝贵的战略资源。为确保这些海量、多源、高价值的科学数据资产的安全、可靠与高效利用,中科院构建并持续完善了科学数据库的数据备份与集中管理服务体系,为全院乃至全国的科学研究提供了坚实的数据基础设施支撑。
一、 科学数据库:科研创新的数字底座
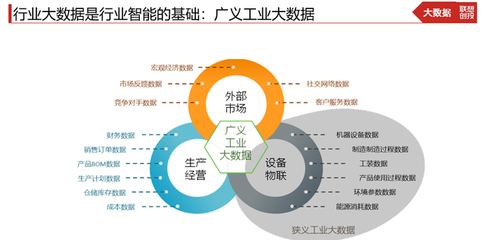
中科院科学数据库涵盖了天文、地理、生物、物理、化学、材料、环境、社会科学等众多学科领域,数据类型包括观测数据、实验数据、模拟数据、文献资料等。这些数据具有体量巨大、增长迅速、结构复杂、价值密度高等特点。传统的分散式、孤岛化的数据管理方式已难以满足数据长期保存、共享应用和安全保障的需求。因此,建立一套体系化、规范化的数据备份与集中管理机制至关重要。
二、 多层次、一体化的数据备份体系
数据备份是抵御数据丢失风险的最后防线。中科院的备份体系遵循“异地、异质、分级”的核心原则:
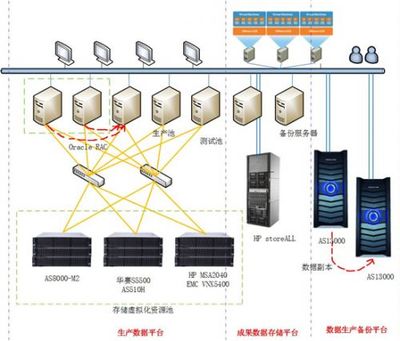
- 本地备份与快速恢复:在主要的数据中心内部,采用高性能存储阵列与备份软件,对关键数据库和文件系统进行定期增量备份和全量备份,确保在硬件故障或逻辑错误时能够快速恢复业务。
- 同城/异地容灾备份:为了防范火灾、洪水等区域性灾难,在物理距离分隔的容灾中心建立数据副本。通过数据同步或异步复制技术,实现数据的异地容灾,保障核心数据的极端可用性。
- 长期归档与磁带库备份:针对需要永久或长期保存的珍贵科研历史数据、原始记录等,采用磁带库等成本较低、稳定性高的介质进行归档备份,满足法规遵从和科学传承的需求。
- 云备份策略:部分非敏感或公开共享数据,逐步探索采用私有云或混合云架构进行备份,利用云的弹性扩展能力,优化备份资源的管理与成本。
整个备份流程实现了自动化调度、完整性校验和状态监控,确保备份任务可靠执行,备份数据可验证、可恢复。
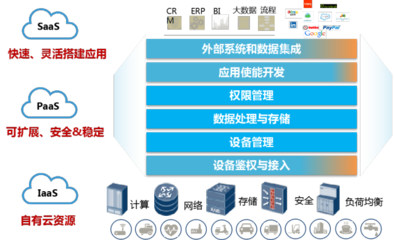
三、 集中化、智能化的数据管理服务
集中管理是提升数据治理水平、挖掘数据价值的关键。中科院的数据集中管理服务聚焦于以下几点:
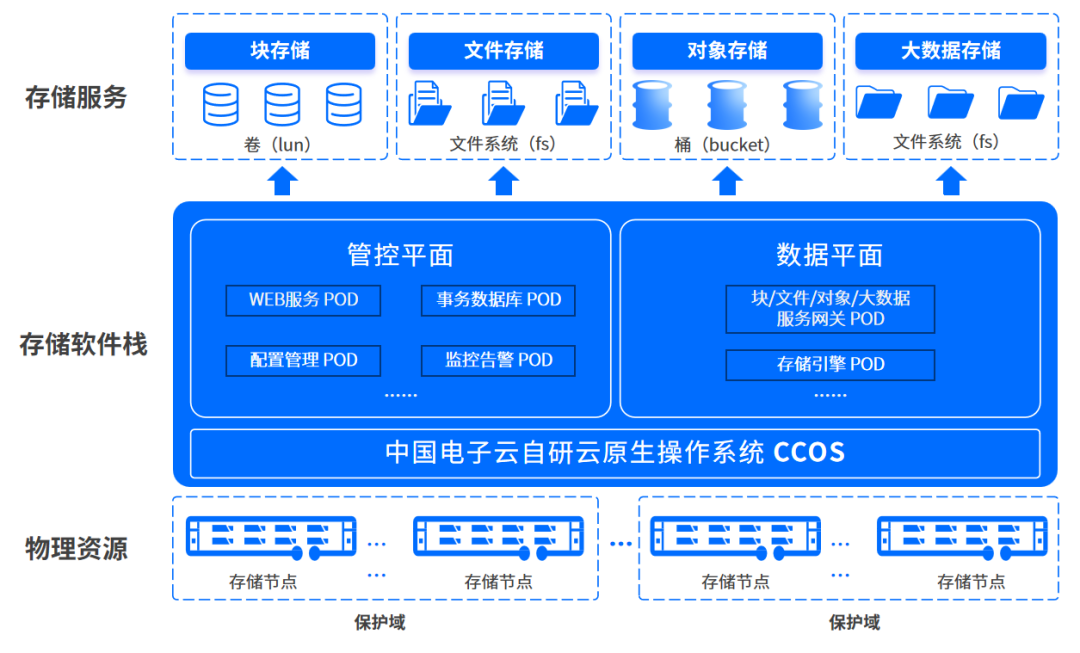
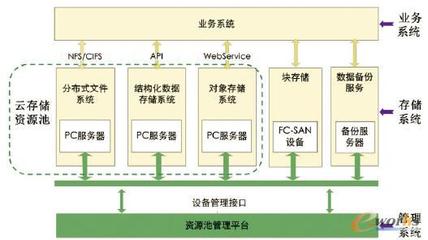
- 统一存储平台:建设或整合大规模、高性能的分布式存储系统(如对象存储、并行文件系统),为各研究所提供统一的存储资源池。研究人员无需自建小型存储服务器,可按需申请存储空间和IO性能,实现了资源的集约化管理和弹性供给。
- 标准化数据汇交与元数据管理:制定科学数据汇交的标准规范,要求重大科研项目产生的数据在验收后汇交至院级或所属学科的数据中心。建立统一的元数据标准与目录系统,对入库数据进行规范化描述,形成全院可检索的数据资源地图,极大促进了数据的发现与交叉复用。
- 全生命周期管理:对数据从产生、处理、分析、发布到长期保存的全生命周期进行跟踪和管理。设定数据的保存期限、访问权限、共享策略,并自动化执行数据迁移、销毁等操作,确保数据管理的合规性与科学性。
- 数据处理服务集成:在集中管理平台之上,逐步集成高性能计算(HPC)、人工智能训练、大数据分析等数据处理环境。提供“数据原地计算”能力,避免海量数据在网络间迁移的瓶颈,支撑从原始数据到科学发现的快速转化,形成“存算一体”的服务模式。
- 安全与审计:建立涵盖网络安全、数据加密、访问控制、行为审计的多层次安全防护体系。确保敏感数据的安全,同时完整记录数据的访问、使用和流动情况,满足科研诚信和数据溯源的要求。
四、 挑战与未来展望
尽管已取得显著成效,中科院的数据备份与管理仍面临数据指数级增长带来的成本压力、多模态数据(如科学影像、流数据)的高效管理、数据跨境流动的安全合规,以及如何更智能化地预测存储需求、自动优化数据布局等挑战。
中科院将进一步加强:
- 绿色节能技术的应用,降低海量数据存储的能耗。
- 主动数据管理与AI赋能,实现基于数据热度和价值的智能分层存储与迁移。
- 联邦学习、隐私计算等新技术在数据共享与安全利用中的探索。
- 与国家科学数据中心体系的深度融合,推动更大范围的科学数据开放共享生态建设。
中国科学院科学数据库的数据备份与集中管理服务体系,如同为国家的科研事业构筑了一座坚固而智慧的“数字仓库”。它不仅守护着科学探索的珍贵记录,更通过高效的数据处理与存储服务,加速了知识发现的进程,为抢占科技制高点、实现高水平科技自立自强提供了不可或缺的数据动能。
如若转载,请注明出处:http://www.aijiasichu.com/product/51.html
更新时间:2026-06-18 19:39:22